(July 2013)

| For the TL;DR crowd:
If your programs are sending and receiving data structures,
you are probably using high-level encapsulations - e.g. XML or JSON.
There are however far more optimal solutions in terms of memory, CPU
and network requirements ; ASN.1 is one of them.
Below you will find a short introduction into the why and how of serialization with ASN.1, as well as hands-on sessions with an open-source ASN.1 compiler implemented under the auspices of the European Space Agency. |
(Do you already know about ASN.1 and/or XML/XSD/JSON? Then feel free to skip this section. Otherwise keep reading).
If you code for a living, you will inevitably end up in a position where two processes are communicating over a link. The link-layer technology itself is not important in this discussion: it can be sockets, or pipes, or whatever else you fancy. What is important, is how you handle the problem of sending your data "across the wire".
In the simplest of cases, you are writing the code at both ends - coding both the server and the client, in the same language.
The easy way - memory dump
In that case, things appear easy enough - for example, assuming you write in C/C++ and send data over sockets, you can just send a memory dump of the message itself:
// The message type struct foo { long msgId; char myflag; float value; unsigned char szDescription[10]; bool isReady; }; // Sender void somefuncThatRunsInTheSendingProcess() { // Populate message data ... struct foo b; b.msgID = ... b.value = ... ... // Send them across send(..., &b, sizeof(b), ...); ... } // Recipient void somefuncThatRunsOnTheReceivingProcess() { ... struct foo b; // Receive message data recv(..., &b, sizeof(b), ...); // Work with them ... }
(how we would handle messages with pointers or references inside them is left as an exercise for the reader - and yes, ignore packet fragmentation for now).
Looks easy and safe enough - block until the data of the structure are read, and work with them.
Until it becomes clear that...
- This code depends on all the fields of the structure being represented in memory in exactly the same way, under both the receiver and sender platforms. If the sender is a 64bit Intel PC, but the receiver is a 32bit ARM-based phone, we have a problem: the long integer field 'msgId' is occupying more space (8 bytes) on the sending machine, than the receiving phone expects (a 4 byte integer).
- The two platforms may have different endianess (little endian vs
big endian). Even if we used 'int' and checked that 'int' uses the same number
of bytes in both sender and recipient, we would still have to rearrange
the incoming bytes of
msgIdto match the target CPU's endianess. - And that's not all ; even if we used 'int' and we rearranged
the bytes to address endianess differences, we would also have to make sure that
the fields are aligned the same way by the two compilers in the two entities
(sender / recipient).
A different structure alignment policy (e.g. how many pad bytes to use between
'myflag' and 'value'?) would wreck havoc in our actual data - and differences
of padding may also lead to a different
sizeof- which would mean overwriting the stack in the recipient... That's when the real "fun" begins... Unpredictable behaviour, based on whether our compilers emit code that detect overflows at run-time by checking buffer canaries ('magic' signatures at both ends of each buffer), or, far worse, emit debugging information in the executable that "hides" the bug... because we overwrite that information instead! - etc, etc... - Finally, imagine maintaining this code across different platforms. That is, you don't have just Intel and ARM - but also PowerPC-based Macs and Itanium based whatevers and made-in-China-phone-somethings.
Using higher-level languages
Some of you may be thinking: 'Yeah, C/C++ causes this kind of mayhem ; use a higher level language'. It could be argued however that there are a lot of markets where using low-level languages like C/C++ is mandatory. Embedded systems are a particularly good example - weak CPUs, little memory available...
But OK, I'll follow along - let's use Python instead:
+-----------------------+ # Sender | Data structure | a = socket(...) | inside Sender process | ... +-----------------------+ a.send( pickle.dumps(myvariable) ) | | +------------+ `----->| Serializer | +------------+ | | | (Link layer - sockets, etc) | | | +--------------+ `->| Deserializer | +--------------+ | | b = socket(...) | +-------------------------+ ... | | Data structure | myvariable = pickle.loads( b.recv(...)) `-->| inside receiver process | +-------------------------+
(if you are thinking about it, for now ignore the fact that the recv() call may fetch only part of the serialized message because of packet fragmentation. For the purposes of this example, assume that we get the exact packet of data sent by the sender in that single recv() call).
This is a definite improvement: Python comes pre-loaded with a generic
serializer. We no longer have to care about what exists inside
myvariable: Integers, float, strings, lists, dictionaries - they
will all safely migrate across different platforms, different CPUs' endianess,
different CPU word sizes, etc:
$ ipython
Python 2.7.3 (default, Mar 5 2013, 01:19:40)
Type "copyright", "credits" or "license" for more information.
In [1]: import pickle
In [2]: a = {'msgId': 1, 'myflag': 'a', 'value': 255,
'szDescription': 'Hello', 'isReady': True}
In [3]: pickle.dumps(a)
Out[3]: "(dp0\nS'msgId'\np1\nI1\nsS'myflag'\np2\nS'a'\np3\nsS'
szDescription'\np4\nS'Hello'\np5\nsS'value'\np6\nI255
\nsS'isReady'\np7\nI01\ns."
In [4]: print pickle.loads(pickle.dumps(a))
{'msgId': 1, 'myflag': 'a', 'szDescription': 'Hello',
'value': 255, 'isReady': True}
We have no clue about how pickle.dumps encodes things, but we don't care ; as
long as they decode fine on the other end, why should we?
Great.
But does this mean that we will code all our software in Python from now on?
Unfortunately, not always an option...
I wish :‑)
As a developer, you will inevitably come to the position where you need to work with other people, that don't care for your preferred language.
Think about it...
How can you send your data structures across, to a program that is written in a completely different language?
Well, if you are really patient and have lots of resources to waste, you can design your own handmade encoding, and manually create encoders and decoders in all the languages you use - taking great pains to make sure the data are transferred correctly in all possible combinations of CPUs, platforms, etc.
Or you could use XML, JSON, or similar generic message representations. But that option too, comes at a price:
- you will be using generic parsers at run-time - causing memory and CPU overhead
- your messages will be encoded in verbose representations - causing network overhead
Or...
Abstract Syntax Notation One (ASN.1)
You saw above that Python did a marvelous job of hiding the message encoding
details by automating the handling of different types in the pickle
module. Wouldn't it be fabulous if we had this kind of machinery across different languages?
Guess what - we do. Since the 1980's, in fact - it's called ASN.1.
The idea behind it is very simple: specify your exchanged message data types in a data description language:
Message ::= SEQUENCE { msgId INTEGER, myflag INTEGER, value REAL, szDescription OCTET STRING (SIZE(10)), isReady BOOLEAN }
The language uses simple constructs to describe data types [1]. SEQUENCEs are what you would call structs or records in other languages - and as you can see, they contain descriptions of their fields. The usual basic types are there: BOOLEAN, INTEGER, REAL, ENUMERATED, OCTET STRING, etc - and SEQUENCEs can contain not only them, but also other SEQUENCEs, or arrays (SEQUENCE OFs).
Once we have written our ASN.1 grammar, we then feed it to an ASN.1 compiler - a tool that reads the specification, and emits, in our desired target language(s), (a) the language-specific type declarations, and (b) two functions per type: an encoder and a decoder, that encode and decode type instances to/from bitstreams.
A hands-on example
First, download the Data Modelling Tools ; a tool suite that contains a free, open-source ASN.1 compiler developed under the supervision of the European Space Agency.
Installing it is easy:
$ wget https://download.tuxfamily.org/taste/DMT/DMT-latest.tgz
...
$ tar zxvf DMT-latest.tgz
...
$ cd DMT-r*
$ ./install.sh
Install in what folder [Default: /opt/DMT] /home/ttsiod/DMT
Installation completed successfully.
The install script will tell you if you are missing any dependencies, and suggest installing them. It will also indicate what to do next:
Now please setup your shell startup scripts to source...
source /home/ttsiod/DMT/DMT_vars.csh
...if you use C-shells, or
source /home/ttsiod/DMT/DMT_vars.sh
...otherwise (bash, etc). You can of course also source these right
now in your current shell, and then run any of the DMT tools ;
they will exist in the PATH (asn1.exe, asn2dataModel, aadl2glueC)
To learn what you can do with the DMT tools, start by reading
'/home/ttsiod/DMT/README' - this will point you to additional docs.
I am using bash, so I follow the second path:
$ echo '. /home/ttsiod/DMT/DMT_vars.sh' >> ~/.bashrc
$ source /home/ttsiod/DMT/DMT_vars.sh
$ which asn1.exe
/home/ttsiod/DMT/tools/asn1scc.3/asn1.exe
$ asn1.exe
No input files
...
Current Version is: 3.0.976
Usage:
asn1 <OPTIONS> file1, file2, ..., fileN
Where OPTIONS are:
...
The ASN.1 compiler is up and running [2].
Here's what the ASN.1 compiler creates when it is invoked on our simple ASN.1 grammar:
$ cat sample.asn
MY-MODULE DEFINITIONS AUTOMATIC TAGS ::= BEGIN Message ::= SEQUENCE { msgId INTEGER, myflag INTEGER, value REAL, szDescription OCTET STRING (SIZE(10)), isReady BOOLEAN } END
$ asn1.exe -c -uPER sample.asn
$ ls -l
total 220
-rw-r--r-- 1 ttsiod ttsiod 22131 Jun 18 17:36 acn.c
-rw-r--r-- 1 ttsiod ttsiod 19479 Jun 18 17:36 asn1crt.c
-rw-r--r-- 1 ttsiod ttsiod 16467 Jun 18 17:36 asn1crt.h
-rw-r--r-- 1 ttsiod ttsiod 12757 Jun 18 17:36 ber.c
-rw-r--r-- 1 ttsiod ttsiod 48772 Jun 18 17:36 real.c
-rw-r--r-- 1 ttsiod ttsiod 254 Jun 18 17:36 sample.asn
-rw-r--r-- 1 ttsiod ttsiod 51789 Jun 18 17:36 sample.c
-rw-r--r-- 1 ttsiod ttsiod 4098 Jun 18 17:36 sample.h
-rw-r--r-- 1 ttsiod ttsiod 24443 Jun 18 17:36 xer.c
$ gcc -c -I . *.c
$ echo $?
0
So, a number of .c and .h files were generated, which GCC then successfully compiled.
The 'gateway' - the only file you need to care about - is sample.h. Remember in our description above, we said:
... an ASN.1 compiler reads this specification, and emits, in our desired target languages, (a) the language-specific type declaration, and (b) two functions per type: an encoder and a decoder, that encode and decode type instances to/from bitstreams.
This is the type declaration that ASN1SCC generated for our message:
$ cat sample.h ... typedef struct { asn1SccSint msgId; asn1SccSint myflag; double value; Message_szDescription szDescription; flag isReady; } Message; ...
asn1SccSint is a typedef inside the Run-time library (asn1crt.h) - and is defined as a 64bit int. Similarly, flag is typedef-ed to bool. So, the ASN.1 compiler generated a semantically-equivalent transformation of the ASN.1 grammar, into our target language's declaration of the corresponding types.
We also said the ASN.1 compiler generates two functions - an encoder, and a decoder. And indeed:
$ cat sample.h ... flag Message_Encode( const Message* val, ByteStream* pByteStrm, int* pErrCode, flag bCheckConstraints); flag Message_Decode( Message* pVal, ByteStream* pByteStrm, int* pErrCode);
- the Encode function takes a pointer to an instance of the type, and a pointer to a ByteStream ; and will encode the fields of the message into a ByteStream (a simple data structure defined inside the Run-time Library, that can store a number of bytes [3]).
- the Decode function does the reverse work: it takes a pointer to an instance of the type (where it will decode into), and a pointer to a ByteStream. It will decode the fields of the message from the encoded representation inside pByteStrm (which, remember, you don't care about ; think of the magic string that Python generated when we called the
pickle.dumpsfunction). - The Encode function also takes a pointer to an integer, where it will store an error code (if an error occurs). What kinds of errors can occur, you ask? In the case of our simple ASN.1 grammar, there is indeed no way to fail - but if we change it to this...
Message ::= SEQUENCE { msgId INTEGER (0..10000), myflag INTEGER, value REAL, szDescription OCTET STRING (SIZE(10)), isReady BOOLEAN }
...then the ASN.1 compiler generates an error code definition:
#ifndef ERR_Message_msgId #define ERR_Message_msgId 1003 /*(0 .. 10000)*/ #endif
...and it is this error code that will be stored inside pErrCode, if we violate the constraint. That is, if we call Encode with an invalid value inside the .msgId field of the val argument, the encoder will report this error code.
In case you missed it, or it wasn't clear enough:
In ASN.1, we can specify not only the field types, but also limits on their values - and have them automatically checked!
And that's the main idea. You can use this generated C code in your projects - it will just work. There are no external dependencies, no libraries to speak of, the code is there, open, for you to use as you please. Note that the encoders will properly handle all manner of potential mischief: endianess of the platform you compile it on, word sizes, etc. You can be sure that by using ASN.1, your encoded messages (that is, the representations inside the ByteStreams) can be sent to whatever platform you fancy, and they will decode fine, into the receiving platform's variables.
(Note: ASN1SCC is made specifically for embedded, safety-critical systems, so it only addresses ASN.1 grammars containing bounded (in size) messages. ASN.1 itself has no such limitation - e.g. you can model open-ended SEQUENCEOFs with it).
What if I have more than one message? Complex ones?
Actually, that's what ASN.1 was built for : to allow easy specification of all the messages that will be exchanged between your apps, regardless of their complexity. Here's a more advanced example, showing ENUMERATED types, nesting inside SEQUENCEs, etc:
MyInt ::= INTEGER (0 .. 20) TypeEnumerated ::= ENUMERATED { red(0), green(1), blue(2) } My2ndEnumerated ::= TypeEnumerated AComplexMessage ::= SEQUENCE { intVal INTEGER(0..10), int2Val INTEGER(-10..10), int3Val MyInt (10..12), intArray SEQUENCE (SIZE (10)) OF INTEGER (0..3), realArray SEQUENCE (SIZE (15)) OF REAL (0.1 .. 3.14), octStrArray SEQUENCE (SIZE (20)) OF OCTET STRING (SIZE(1..10)), enumArray SEQUENCE (SIZE (12)) OF TypeEnumerated, enumValue TypeEnumerated, enumValue2 ENUMERATED { truism(0), falsism(1) }, label OCTET STRING (SIZE(10..40)), bAlpha T-BOOL, bBeta BOOLEAN, sString T-STRING, ... }
The language is fairly simple, so you should be able to figure out what is going on. If not, you can study Olivier Dubuisson's freely available book for an extensive treatment of ASN.1 - all the way up to advanced features.
Processing this grammar with any ASN.1 compiler (including ASN1SCC), you would be all set to use the ready-made message definitions for AComplexMessage, TypeEnumerated, ... and their corresponding encoders/decoders.
In plain words - the complexity and the number of messages don't matter when you use ASN.1.
And this works for any language?
Yes, there are ASN.1 compilers for almost any language you can think of. ASN1SCC in particular, has been developed under the supervision of the European Space Agency, and it targets C and Ada, with specific emphasis on embedded, safety-critical systems - for which it does some pretty amazing things:
- it never uses any heap - no
mallocis ever called; what would you do in space when your satellite runs out of heap? Blue screen? :‑) - it can automatically generate test cases (i.e. instances of the ASN.1 grammar's messages), that will exercise the encoders and the decoders at full 100% coverage (very important for safety critical systems)
- if you use SPARK/Ada, it emits code contracts, that a static compile-time verifier can prove ; making it absolutely certain that no such errors can occur at runtime.
- it generates human-readable code (as opposed to other ASN.1 compilers that emit very cryptic code - chains-of-function-pointers-in-global-structures...)
- ...and has various other interesting features.
Suffice to say, if you are involved with embedded development, it's worth taking a look.
Isn't XML/JSON better than this?
Well, it depends on your definition of 'better'.
If you value optimal encoding/decoding performance, minimal encoded message size, guarantees of code safety, and minimal power requirements for encoding/decoding messages, then no, XML is most definitely NOT better. That's why your mobile phone has used ASN.1 encoding while you were reading this article. I am not kidding - almost every single signalling message that your phone sends to the local cell tower, is encoded via ASN.1!
If on the other hand...
- you don't care for performance or safety requirements, and XML parsing is cheap in your problem domain
- you have lots of memory to waste and don't care about optimal message representations
- you want to easily peek into the encoded streams and figure out things during debugging (but read below for XER, and also note that wireshark has an ASN.1 inspector)
- you have other development dependencies, like extensive use of XPath...
... then yes, XML/JSON may be a better match for you.
What about CORBA? Or other middleware tech?
Let me repeat: If you care about optimal encoding/decoding performance, optimal memory use, ...
Remember, when we are speaking about ASN.1, we are looking at technology that was built by the Ancients. Being optimal wasn't a choice, back then - it was mandatory. You didn't have resources to waste. When you use ASN.1, you simply automate the parts of message marshalling that can be automated, without losing any performance or wasting any memory.
Do a low-level comparison of ASN.1 with any other technology that involves marshalling, and I guarantee you will be paying something at runtime: memory use, performance, or both.
How does ASN.1 represent the messages on the wire?
ASN.1 comes with a set of predefined rules, that specify how encoding is done. You choose one when you invoke the ASN.1 compiler on your ASN.1 grammar - ASN1SCC, for example, currently supports four:
- Basic Encoding Rules (BER), is the most basic one: it emits a stream comprised of Tags, Lengths, and Values per each field (TLV-encoding). As such, it is a rather verbose encoding, but it is extremely easy to decode - no CPU overhead whatsoever.
- Packed Encoding Rules (PER), and in particular, Unaligned PER (UPER), is the most "space-optimal" encoding, packing field information as tightly as possible. In PER, for example, when you specify that an INTEGER field has a constraint of (0..15), only 4 bits will be used in the encoded stream to represent it.
- XML Encoding Rules (XER), is using an XML representation for the data - so you can use ASN.1 and enjoy type-safe declarations inside your languages, but have an easily inspectable format (on the wire).
- Finally, ACN is a custom, advanced encoding that allows you to control the details of the encoding yourself - but that's too advanced for this too-big-already-blog post.
Note that choosing encoding has zero impact on your type declarations - you can switch between encodings without changing anything in your user code, except the name of the encoding/decoding function you call: e.g. instead of the default encoding (UPER), where you call Message_Decode, you'd call Message_BER_Decode - etc.
OK, I see it now - this can be useful
ASN.1 basically allows your programs to communicate with implementations coded in other languages, by establishing common ground - through a simple [1] data definition language. If you use it, arbitrarily complex messages are handled easily: think of arrays containing unions containing structs - or, in ASN.1 parlance, SEQUENCE OFs containing CHOICEs containing SEQUENCEs). You don't have to ever implement any serializers/deserializers of the messages, and provided you use a compiler like ASN1SCC, you also get guarantees of correctness, type safety and performance - for free.
And then, you realize you can do some magic...
Equally important - and this is a matter for another blog post, but consider this a teaser - by using ASN.1 to define your messages, you can then automatically create many things that are depending on the message definitions: in the case of the work I've done for the European Space Agency, we've built automatic translators of ASN.1 messages towards...
Code generated by modelling tools: building automatic 'translators' of code generated by modelling tools to/from ASN.1, we can then use ASN.1 as the center of a star-formation, and have code generated by one modelling tool automatically "speak" to code generated by another, at runtime:
- Simulink Real-time workshop
- SCADE
- ObjectGeode and OpenGeode
- Real-time Developer Studio
SQL databases: we can automatically store and retrieve arbitrarily complex ASN.1 messages inside automatically constructed databases (no, not via BLOBs - with tables that perfectly mirror the relationships between types using foreign keys:
- PostgreSQL
- MySQL
- SQLite
- ...and many other SQLAlchemy-supported DB engines (more details in the TASTE wiki).
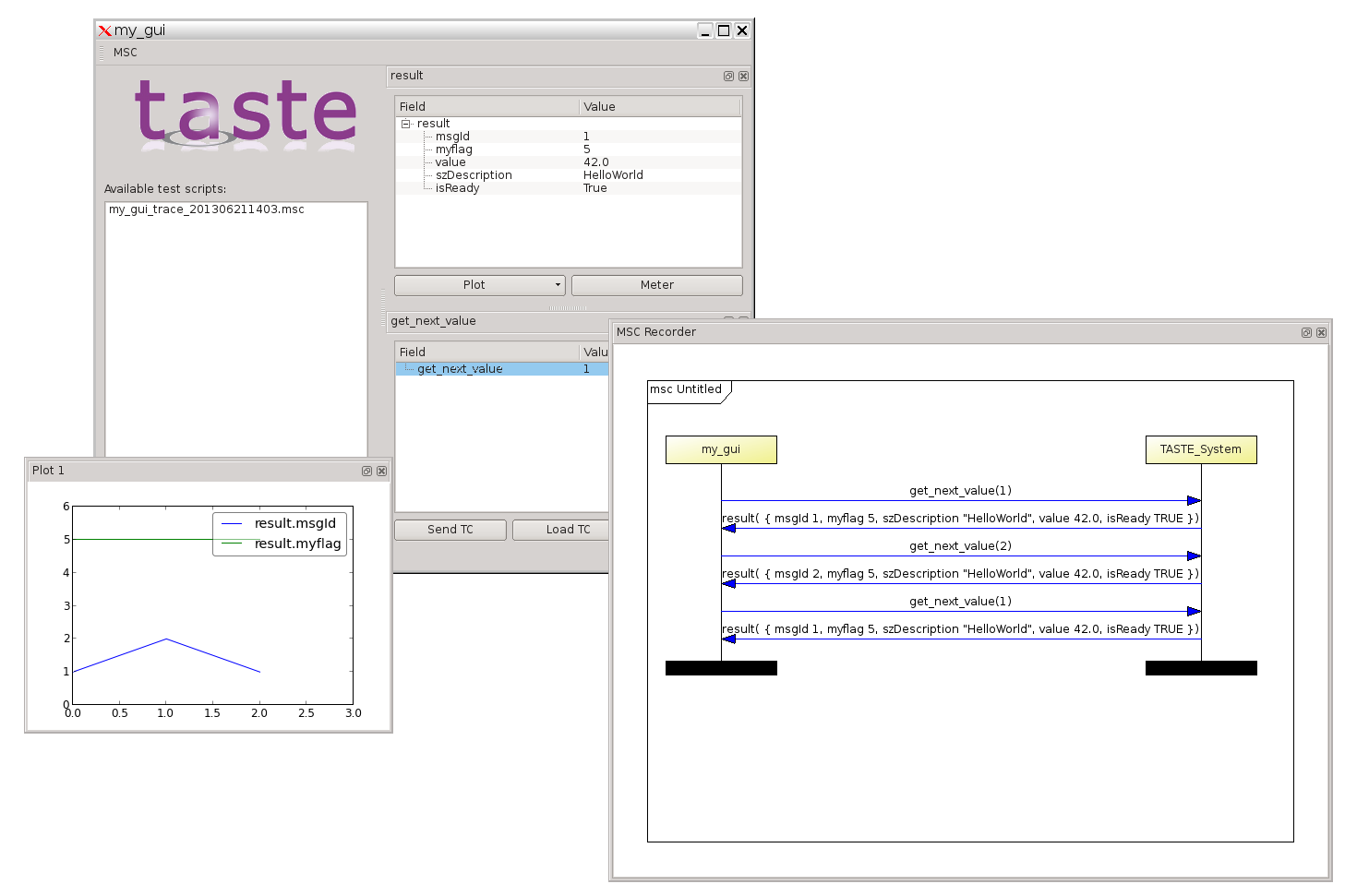
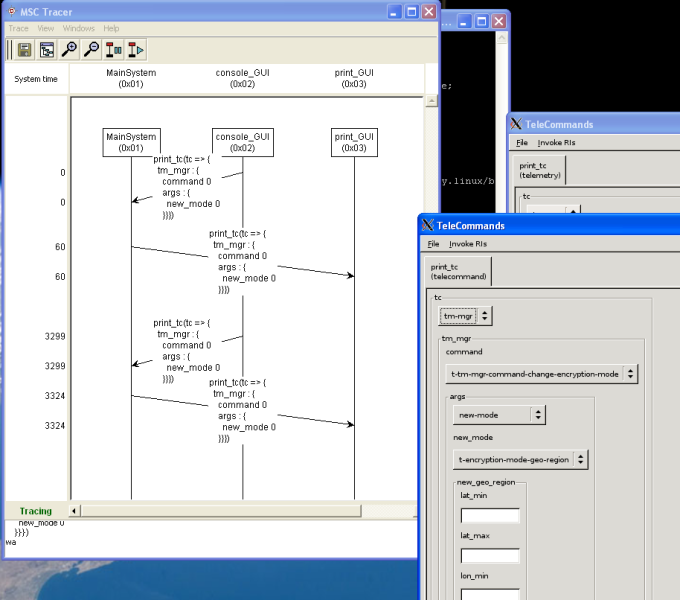
Automatically generated graphical user interfaces receiving and sending TM/TCs (Telemetry and Telecommands) to and from our satellites.
Automatically generated graphical message tracers to allow for graphical monitoring of what happens to a running system - and why.
Automatically generated Interface Control Documents (ICDs) that describe the binary representation of the stream - for those people, that for whatever reason, choose to write encoders/decoders on their own:
...and loads more. Visit this for a 5 min showcase, or the official site for more info. You can also peruse the manual and see how ASN.1 (and AADL) allowed us to describe complex real-time embedded systems and their messages, in succinct ways that generate optimal code.
{kind=link}
{kind=link}
{kind=link}
Two examples of ASN.1-based mappers: A SWIG-based python wrapper, and a SQL exporter
The following is a hands-on example of how our SWIG-based Python mapper - bundled in our DMT tools - wraps around the UPER C functions generated by ASN1SCC, and allows Python code to speak with ASN.1 UPER encoded data:
$ cat sample.asn
MY-MODULE DEFINITIONS AUTOMATIC TAGS ::= BEGIN Message ::= SEQUENCE { msgId INTEGER(0..10000), myflag INTEGER(0..255), value REAL(0.0 .. 3.14159), szDescription OCTET STRING (SIZE(1..10)), isReady BOOLEAN } END
$ mkdir pythonOutput
$ asn2dataModel.py -toPython -o pythonOutput/ sample.asn
$ cd pythonOutput
$ make -f Makefile.python
$ ...
... which then gives you a full API over your ASN.1 types, through Python classes:
$ cat test.py
from sample_asn import * # Create a buffer big enough for the maximum form of the PER-encoded data) d1 = DataStream(DV.Message_REQUIRED_BYTES_FOR_ENCODING) # Create an instance of the message and set the fields) msg = Message() msg.msgId.Set(5) msg.myflag.Set(15) msg.value.Set(2.718) msg.szDescription.SetFromPyString("Hello!") msg.isReady.Set(True) # Encode the message as per ASN.1 UPER encoding rules msg.Encode(d1) # Get the encoded binary data - send them with sockets/pipes/whatever... b = d1.GetPyString() # ...and eventually place them in a buffer and use them # as a source for decoding on the receiver code: d2 = DataStream(DV.Message_REQUIRED_BYTES_FOR_ENCODING) d2.SetFromPyString(b) msgReceived = Message() msgReceived.Decode(d2) print "Received msgId:", msgReceived.msgId.Get() print "\nAll fields:\n" msgReceived.PrintAll()
$ python ./test.py
Received msgId: 5
All fields:
msgId:
5
myflag:
15
value:
2.718
szDescription:
Hello!
isReady:
True
$
The code shows a full round-trip that passes from structure, to byte buffer, and back to structure.
Similarly, here's our SQL mapper, automatically generating the SQL schema for storing/retrieving our messages:
$ asn2dataModel.py -toSQL sample.asn
$ ls -l
total 16
drwxr-xr-x 2 ttsiod ttsiod 4096 Jun 20 11:15 ./
drwxr-xr-x 18 ttsiod ttsiod 4096 Jun 20 10:55 ../
-rw-r--r-- 1 ttsiod ttsiod 261 Jun 20 11:15 sample.asn
-rw-r--r-- 1 ttsiod ttsiod 1232 Jun 20 11:15 sample.sql
$ cat sample.sql
-- SQL statements for types used in "sample.asn" CREATE TABLE Message_msgId ( id int PRIMARY KEY, data int NOT NULL, CHECK(data>=0 and data<=10000) ); CREATE TABLE Message_myflag ( id int PRIMARY KEY, data int NOT NULL, CHECK(data>=0 and data<=255) ... CREATE TABLE Message ( id int NOT NULL, msgId_id int NOT NULL, myflag_id int NOT NULL, value_id int NOT NULL, szDescription_id int NOT NULL, isReady_id int NOT NULL, CONSTRAINT Message_pk PRIMARY KEY (id), CONSTRAINT msgId_fk FOREIGN KEY (msgId_id) REFERENCES Message_msgId(id), CONSTRAINT myflag_fk FOREIGN KEY (myflag_id) REFERENCES Message_myflag(id), CONSTRAINT value_fk FOREIGN KEY (value_id) REFERENCES Message_value(id), CONSTRAINT szDescription_fk FOREIGN KEY (szDescription_id) REFERENCES Message_szDescription(id), CONSTRAINT isReady_fk FOREIGN KEY (isReady_id) REFERENCES TaStE_Isready_type(id)); $
As you can see, the transformation is also converting ASN.1 constraints to SQL constraints - and more importantly, works regardless of the complexity of the message.
Conclusion
Putting it simply: ASN.1 is another technology that is optimal for certain problem domains - and yet people will ignore it and pay the penalty in performance, memory and robustness.
By modelling your system's messages, ASN.1 also allows for lots of automatic code generation. In our case, we identified tremendous opportunities for automation, and have made a number of ASN.1-based code generators, that, among other things, automatically...
- generate graphical user interfaces
- integrate code generated by different modelling tools
- generate formal wire-format documentation
- generate Python classes that serialize instances of the ASN.1 types to/from a database (regardless of database engine).
- generate the skeleton code of an FPGA (.vhdl files) as well as the complete software driver that will speak to it at runtime, interfacing it with any other code that speaks ASN.1
- etc...
Fellow developers, have a look. You may find out ASN.1 can make your work easier, simpler, and more efficient.
Notes
If you are unfortunate enough to come into contact with lots of Telecom standards, you will often see how a simple and useful idea can become ridiculously complex as feature creep takes hold. To whatever extent you can, resist this - in the case of ASN.1, I humbly suggest that you use only the basic principles: type specification and constraints.
The compiler is an F# application, so it can run (via Mono) under Linux and OS X, or natively under Windows (to put it simply: it works on all major platforms). Why it is written in F# is a matter for another blog post - suffice to say, OCaml (the mother of F#) is a language with a strong type system that prevents many potential issues, detecting them at compile-time. It is very important for any code generator (and an ASN.1 compiler is exactly that!) to detect as many errors as possible at compile-time.
Since ASN1SCC targets embedded platforms, memory is an issue (we don't want to allocate stuff from the heap, since the heap may run out - when you're in space, what can you do if you run out of heap?...). The compiler therefore emits
#defines that allow us to reserve the necessary memory during compile-time:
void foo() { static Message decodedPDU; static byte encBuff[Message_REQUIRED_BYTES_FOR_ENCODING]; static BitStream bitStrm; BitStream_Init(&bitStrm, encBuff, Message_REQUIRED_BYTES_FOR_ENCODING); ret = Message_Encode(pVal, &bitStrm, pErrCode, TRUE); ...


| Index | CV | Updated: Sat Oct 8 12:39:34 2022 |